객체 탐지(ObjectDetection)이란?
컴퓨터 비전 중, 카메라를 통해 얻을 수 있는 이미지 스트림에서 물체를 인식하는 기술을 의미합니다.
YOLO(You Only Look Once)
딥러닝을 통한 객체 탐지 모델은 크게 R-CNN, SSD, YOLO가 있습니다. 객체탐지 모델들이 우선적으로 당면한 문제 중 하나는, 실제 서비스를 할 수 있을 만큼 탐지 속도와 정확도를 올려야 한다는 겁니다. 정확도와 탐지 속도(mAP : mean Average Precision)는 trade-off 관계입니다. 탐지 속도가 높으면 그만큼 정확도는 낮아지고, 정확도가 낮아지면 그만큼 탐지 속도가 올라갑니다. YOLO는 괜찮은 수준의 mAP와 FPS를 가집니다. 개인 레벨에서 시범적으로 사용해보기에는 최적의 모델이라 할 수 있겠습니다.
YOLO(You Only Look Once)의 원리

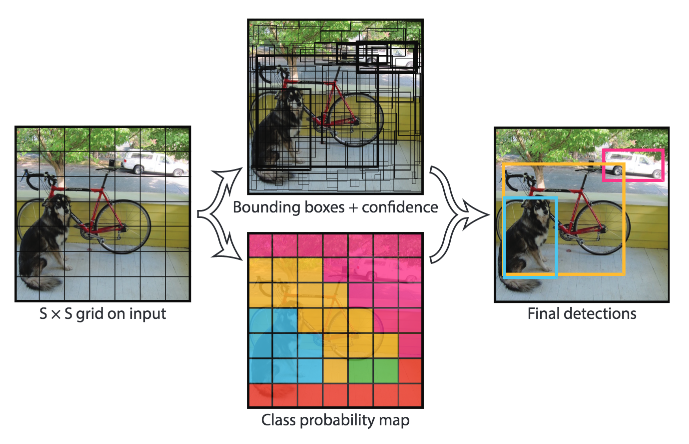
YOLO는 한 개의 네트워크에서 탐지를 원하는 물체의 영역(bounding box)와 이름을 표시합니다. 원리는 다음과 같습니다.
1. 이미지를 입력으로 받습니다.(한 장의 이미지이든 비디오이든 웹캠 스트림이든, 컴퓨터 캡쳐 화면이든 nparray로 치환할 수 있다면 뭐든지 받습니다.)
2. S x S 크기의 그리드로 이미지를 나눕니다. 각 그리드에서 예측을 한 후 이를 종합해서 bounding box를 구성합니다.
PyTorch에서 YOLO 사용해보기
eriklindernoren/PyTorch-YOLOv3
Minimal PyTorch implementation of YOLOv3. Contribute to eriklindernoren/PyTorch-YOLOv3 development by creating an account on GitHub.
github.com
$ git clone https://github.com/eriklindernoren/PyTorch-YOLOv3
$ cd PyTorch-YOLOv3/
$ sudo pip3 install -r requirements.txt
$ cd weights/
$ bash download_weights.sh
$ cd data/
$ bash get_coco_dataset.sh
python3 detect.py --image_folder data/samples/4. 3.에서 받은 샘플 이미지로 detect를 수행합니다.

5. data/samples에 있는 raw 데이터가 YOLO 모델을 통과한 후 bounding box 가 적용되어 있는 것을 볼 수 있습니다.
참고자료
질문이 있으시다면 댓글 남겨주세요. 실시간으로 답변 드리겠습니다.
글이 도움이 되셨다면 왼쪽 아래의 공감버튼과 광고 클릭 부탁드립니다. 고마움을 표현할 수 있는 가장 쉬운 방법입니다.
감사합니다.