
Introduction
이미지 처리 파이프라인을 구축하다보면 성능에 대한 문제에 아주 많이 부딪힙니다. 영상처리라는 작업 자체가 리소스를 많이 활용하다보니, 이를 어떻게 해야 준수한 성능을 내게 만들 수 있을지에 대해 고민을 하게 됩니다. 이 고민에 대한 해결책의 방향은 크게 두 가지가 있습니다. 주어진 자원을 최대한으로 활용하거나, 주어진 자원 자체를 최적화 시키는 것입니다. 여기에서 주어진 자원자체를 최적화 시킨다는 것은 하드웨어 자체에 내장 가속 칩이 존재해서 그 작업을 해당 칩에 위임하는 것을 말합니다. 가장 쉽게 접할수 있는 예가 GPU 혹은 CPU/GPU 내부에 통합된 비디오 가속 칩이 있겠습니다.
난 죽어도 파이썬을 써야겠다.
가장 접근하기 쉬운 것은 자원 자체를 최적화 하는 것입니다. 병렬처리가 그 중 한 가지 방법이라 할 수 있겠습니다. 간단한 작업의 경우 스레드를 여러개 만들어서 해결을 하거나 여러 프로세스를 활용하는 방법이 있겠습니다. 이런 측면에서는 C++이 파이썬보다 낫습니다. 그러나 저는 죽어도 파이썬을 써야겠습니다. 그래서 방법을 찾았습니다.
How it Works?
이렇게 프로세스 간 통신(IPC)를 해야 할 경우, 파이프나 tcp/udp를 쓸 수 있겠습니다. 혹은 C++에서는 shared memory 개념을 사용할 수 있습니다. 곧죽어도 파이썬을 써야 하는 경우, A 프로세스에 이미지를 넘겨주기 위해 이미지 배열을 직렬화 / 역직렬화해서 보내줍니다. 이것이 이 포스팅에서 말하려는 주된 내용입니다. 컴퓨터를 이해가 어려운 C부터 정석대로 배워왔다면 상대적으로 쉽게 이해할 수 있는 개념입니다.
영상은 3차원이고, 메모리는 1차원이다.
영상은 3차원이고, 메모리는 1차원이다.
영상은 ((R,G,B), 높이, 너비) 3차원의 깊이를 가지고 있습니다. 그런데 우리가 활용하려는 메모리는 1차원입니다. 따라서 영상을 보낼 때, 보내는 측에서 배열을 1차원으로 만들어주고(data serialization), 받는 측에서 원본 영상의 shape으로 변형시켜주면 올바르게 활용이 가능합니다.
Dependency
python 3.11
opencv
multiprocessing
Broadcaster.py
from multiprocessing import shared_memory
import numpy as np
import cv2
TARGET_WIDTH = 960
TAREGET_HEIGHT= 540
TARGET_DEPTH = 3
video_path = '1.mp4'
sample_array = np.zeros((TAREGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH), dtype=np.uint8) # (600768,)
stream_shm = shared_memory.SharedMemory(name ='shm',create=True, size=sample_array.nbytes)
if __name__ == '__main__':
cap = cv2.VideoCapture(video_path)
# 영상 파일이 정상적으로 열렸는지 확인
if not cap.isOpened():
print("영상 파일을 열 수 없습니다.")
exit()
# 영상의 프레임 너비와 높이 가져오기
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 출력할 창 생성
cv2.namedWindow('Broadcasting', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Broadcasting', frame_width, frame_height)
while True:
# 영상에서 프레임 읽기
ret, frame = cap.read()
# 프레임을 제대로 읽지 못한 경우 종료
if not ret:
break
# 프레임 출력
cv2.imshow('Broadcasting', frame)
shared_a = np.ndarray(frame.shape, dtype=frame.dtype, buffer=stream_shm.buf)
shared_a[:] = frame
if(cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT)):
cap.open(video_path)
# 'q' 키를 누르면 종료
if cv2.waitKey(1) == ord('q'):
break
stream_shm.unlink()
stream_shm.close()
cap.release()
cv2.destroyAllWindows()세부적인 스킬보단 전체 흐름을 대강 보는게 더 중요할 것 같아 별도의 refactoring은 거치지 않았습니다. frame을 어떻게 shared memory buffer에 저장하는지만 보시면 되겠습니다. 이 부분만 대강 보고서 gpt한테 짜 달라면 잘 짜 줄거에요.
Receiver.py
from multiprocessing import shared_memory
import numpy as np
import cv2
TARGET_WIDTH = 960
TAREGET_HEIGHT= 540
TARGET_DEPTH = 3
def arr_steam_player(shm_name, shape=(TAREGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH)):
# Shared Memory 테스트용, shared 메모리로부터 배열을 받아서,
# print('[arr_stream] getting ')
existing_shm = shared_memory.SharedMemory(name=shm_name)
shared_a = np.frombuffer(existing_shm.buf, dtype=np.uint8)
c = np.ndarray(shape, dtype=np.uint8, buffer=existing_shm.buf)
print(type(c))
print(shared_a.shape, c.shape)
while True:
cv2.imshow('SharedMemory_player', c)
if cv2.waitKey(int(1000 / 24)) == ord('q'):
break
existing_shm.unlink()
existing_shm.close()
# 영상 파일과 창 닫기
cv2.destroyAllWindows()
if __name__ == '__main__':
arr_steam_player('shm')Broadcaster.py에 저장된 shared memory의 shape을 복원하여 opencv로 출력하고 있습니다. 마찬가지로 보내는 측과 받는 측의 데이터 serialization/deserialization 과정만 보시면 되겠습니다.
Result
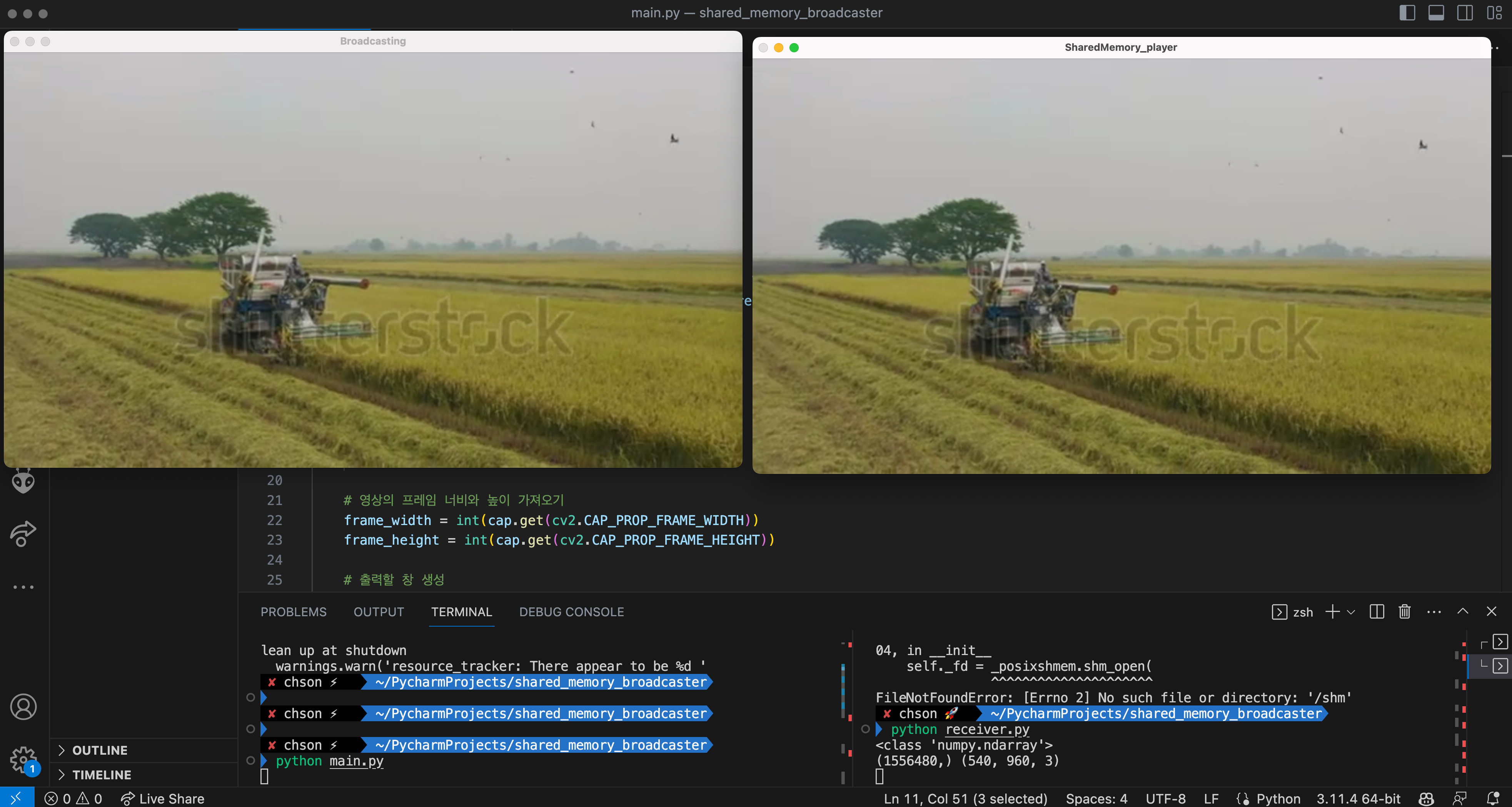
송신측과 수신측의 shared memory의 이름과, 통신할 이미지의 크기만 맞춰주면 데이터가 서로 다른 프로세스 간에 전송되는 것을 보실 수 있습니다. 사실 만든지는 오래 되었는데 맥에서 구현해보니 sharedmemory 이름을 못 찾는 문제가 생겨서 포스팅 늦추다 이제서야 올립니다. 아마 sharedmemory 구현 방식이 posix 환경과 win32api를 활용하는 과정에서 미묘하게 다른 동작을 보이는 모양입니다. 이미지 ipc 구현을 위한 별도의 임시 파일을 만들어서, 서로의 shared memory 이름와 shape를 공유하는 식으로 코드를 작성한다면 맥에서도 큰 문제 없이 작동할 것으로 보입니다.
Shape을 다르게 해 보면 어떨까?
여기에서는 보내는 측의 shape이(960,540,3) 이었습니다. 받는 측도 동일하게 설정된 상태라 정상적으로 나왔습니다. 여기에서, 받는 측의 shape이 조금 다르다면 어떻게 될까요?
import numpy as np
import cv2
# TARGET_WIDTH = 960
# TAREGET_HEIGHT= 540
TARGET_WIDTH = 1080
TAREGET_HEIGHT= 480
TARGET_DEPTH = 3960*540 = 518400인데, 1080*480 역시 518400으로 같습니다. 그렇다면 어찌저찌 하여 프레임의 데이터를 잘 표시할 수 있을 것만 같습니다. 실행시켜보면 다음과 같이 나옵니다.
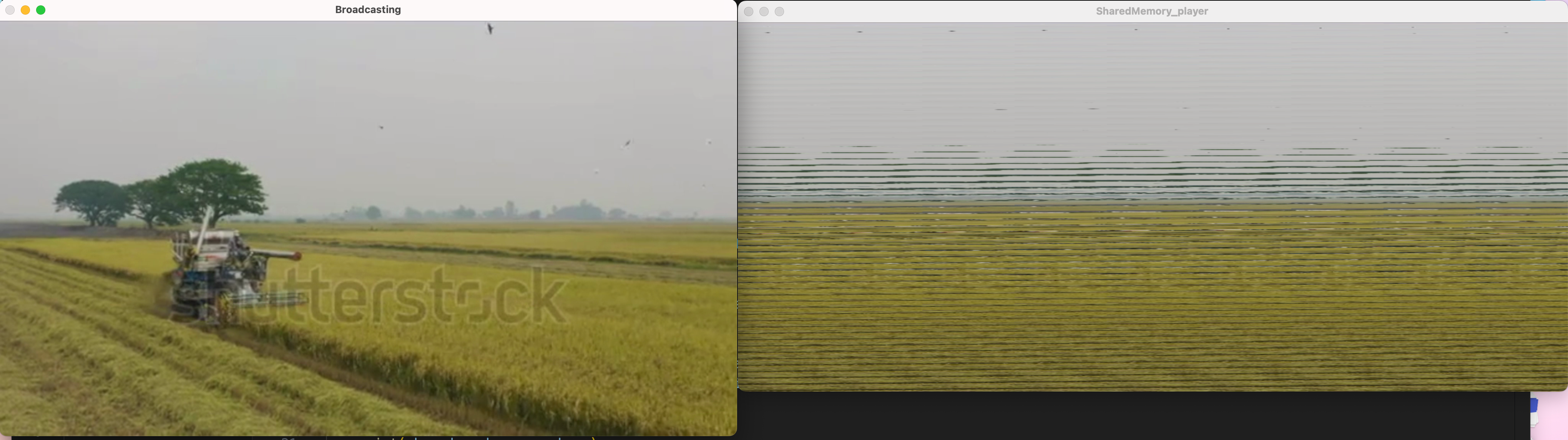
나오긴 하는데 어쩐지 찌그러져 보입니다. 이번에는 599*539으로 1픽셀씩 모자르게 deserialization된 데이터를 보겠습니다.
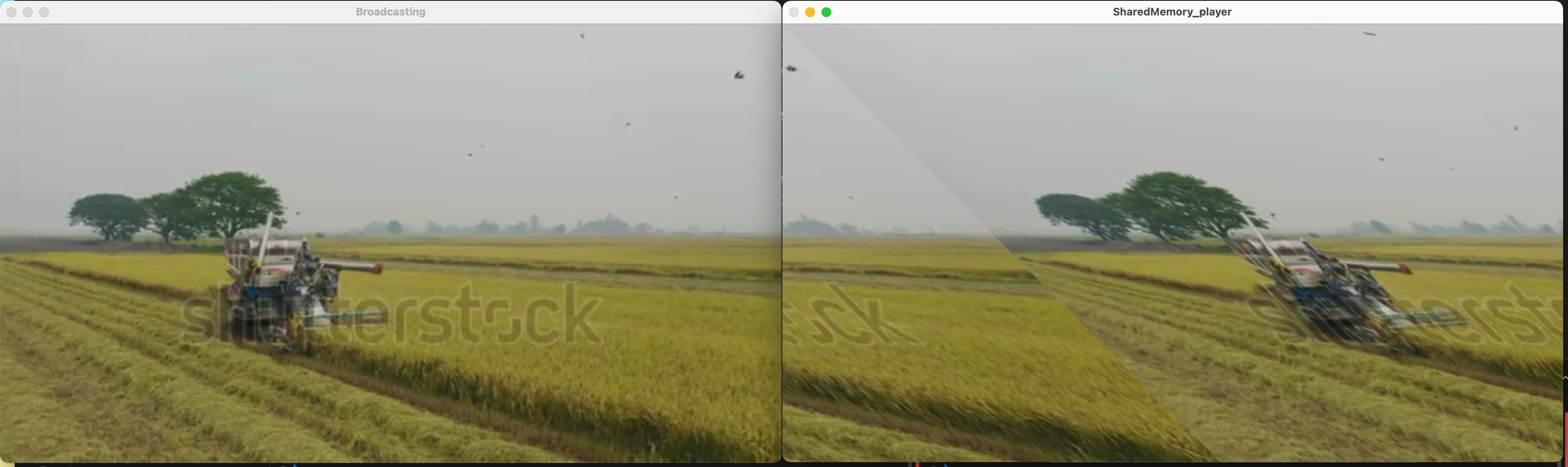
우리가 아날로그 TV의 노이즈에서 보는 것과 비슷한 현상이 발생하는 것을 볼 수 있습니다. 비단 아날로그TV 뿐 아니라, 이미지를 디스플레이 드라이버에서 디스플레이로 전달하는 데 문제가 생길 수도 있습니다. 이런 문제로 아이패드 미니6의 젤리스크롤 현상이 이슈가 되었습니다. 지금 우리가 테스트한 것 처럼 어떤 데이터 소스로부터 영상을 받아서 표현하는데 문제가 생기는가 하면, 이미지 센서로부터 값을 한 번에 모두 읽어오는 데도 비슷한 문제가 발생할 수 있음을 확인할 수 있습니다. 각자 문제의 원인은 조금씩 다르지만, 병목에 의해 문제가 발생했다는 점에서는 흥미롭게 볼 수 있겠습니다. 다음의 글들을 읽어보세요.
Global shutter VS Rolling Shutter 비교 | Vieworks Machine Vision Blog
움직이는 물체를 촬영하면 Rolling shutter 에서는 젤로 현상이 발생합니다. 그래서 Global shutter가 항상 좋다고 생각하는 분들이 많습니다. 하지만 글로벌 셔터와 롤링 셔터는 서로 다른 장단점을 갖
visionblog.vieworks.com
아이패드 미니6 젤리스크롤이 생기는 이유
전세계 공통 현상 디스플레이에 민감하신 분들이 몇몇 계십니다. 이번에 아이패드 미니 6세대를 구매하신 분들 중에서는 이 현상을 불편해하시는 분들이 많을 거라 봅니다. 글쎄요.. 뭐가 이상
yeobie-kim.tistory.com
Done!
gpt가 나오기 전까지만 해도 이런 정보는 삽질을 통해서만 얻어낼 수 있는 값진 결과였습니다. 예전같았으면 신나서 공유했겠지만, 이제는 gpt가 대강 초안을 잘 잡아주니 별로 흥미가 생기질 않습니다. 그래서 좀 포스팅을 미룬 경향이 있었습니다. 근데 한 편으로 생각해보니 gpt만 가지고 코딩을 하다 보면 이런 생각이 필요한 상황에서 gpt의 대화창에 갇혀 새로운 생각 자체를 못하는 케이스가 많아지더라구요. 어찌 보면 당연한 일입니다. 그리고 그 부분에서 저는 개발자의 앞날을 바라보고 싶습니다. 전자시계가 나왔다고 오토매틱 시계가 죽지 않았듯, 인력거꾼이 택시기사로 바뀌었듯, 개발자도 어느 순간 그 성격이 바뀌는 날이 올겁니다. 코더인지 엔지니어인지는 시간과 제 커리어가 답을 해 주겠죠..?
** 본 문서는 다음 내용을 참고하여 작성되었습니다.
[Python] Process간 Numpy Array 공유하기 -2편
devocean.sk.com
긴 글 읽어주셔서 감사합니다. ❤️와 광고 클릭으로 고마움을 간단히 표현할 수 있습니다.
개발 환경(Desktop) | Ryzen 5900X, RTX3080
개발 환경(Laptop) | M1 Macbook Air, M2 Macbook Pro
AI, IoT 제품 개발 및 기타 문의 | dokixote@wklabs.io
Introduction
이미지 처리 파이프라인을 구축하다보면 성능에 대한 문제에 아주 많이 부딪힙니다. 영상처리라는 작업 자체가 리소스를 많이 활용하다보니, 이를 어떻게 해야 준수한 성능을 내게 만들 수 있을지에 대해 고민을 하게 됩니다. 이 고민에 대한 해결책의 방향은 크게 두 가지가 있습니다. 주어진 자원을 최대한으로 활용하거나, 주어진 자원 자체를 최적화 시키는 것입니다. 여기에서 주어진 자원자체를 최적화 시킨다는 것은 하드웨어 자체에 내장 가속 칩이 존재해서 그 작업을 해당 칩에 위임하는 것을 말합니다. 가장 쉽게 접할수 있는 예가 GPU 혹은 CPU/GPU 내부에 통합된 비디오 가속 칩이 있겠습니다.
난 죽어도 파이썬을 써야겠다.
가장 접근하기 쉬운 것은 자원 자체를 최적화 하는 것입니다. 병렬처리가 그 중 한 가지 방법이라 할 수 있겠습니다. 간단한 작업의 경우 스레드를 여러개 만들어서 해결을 하거나 여러 프로세스를 활용하는 방법이 있겠습니다. 이런 측면에서는 C++이 파이썬보다 낫습니다. 그러나 저는 죽어도 파이썬을 써야겠습니다. 그래서 방법을 찾았습니다.
How it Works?
이렇게 프로세스 간 통신(IPC)를 해야 할 경우, 파이프나 tcp/udp를 쓸 수 있겠습니다. 혹은 C++에서는 shared memory 개념을 사용할 수 있습니다. 곧죽어도 파이썬을 써야 하는 경우, A 프로세스에 이미지를 넘겨주기 위해 이미지 배열을 직렬화 / 역직렬화해서 보내줍니다. 이것이 이 포스팅에서 말하려는 주된 내용입니다. 컴퓨터를 이해가 어려운 C부터 정석대로 배워왔다면 상대적으로 쉽게 이해할 수 있는 개념입니다.
영상은 3차원이고, 메모리는 1차원이다.
영상은 3차원이고, 메모리는 1차원이다.
영상은 ((R,G,B), 높이, 너비) 3차원의 깊이를 가지고 있습니다. 그런데 우리가 활용하려는 메모리는 1차원입니다. 따라서 영상을 보낼 때, 보내는 측에서 배열을 1차원으로 만들어주고(data serialization), 받는 측에서 원본 영상의 shape으로 변형시켜주면 올바르게 활용이 가능합니다.
Dependency
python 3.11
opencv
multiprocessing
Broadcaster.py
from multiprocessing import shared_memory
import numpy as np
import cv2
TARGET_WIDTH = 960
TAREGET_HEIGHT= 540
TARGET_DEPTH = 3
video_path = '1.mp4'
sample_array = np.zeros((TAREGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH), dtype=np.uint8) # (600768,)
stream_shm = shared_memory.SharedMemory(name ='shm',create=True, size=sample_array.nbytes)
if __name__ == '__main__':
cap = cv2.VideoCapture(video_path)
# 영상 파일이 정상적으로 열렸는지 확인
if not cap.isOpened():
print("영상 파일을 열 수 없습니다.")
exit()
# 영상의 프레임 너비와 높이 가져오기
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 출력할 창 생성
cv2.namedWindow('Broadcasting', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Broadcasting', frame_width, frame_height)
while True:
# 영상에서 프레임 읽기
ret, frame = cap.read()
# 프레임을 제대로 읽지 못한 경우 종료
if not ret:
break
# 프레임 출력
cv2.imshow('Broadcasting', frame)
shared_a = np.ndarray(frame.shape, dtype=frame.dtype, buffer=stream_shm.buf)
shared_a[:] = frame
if(cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT)):
cap.open(video_path)
# 'q' 키를 누르면 종료
if cv2.waitKey(1) == ord('q'):
break
stream_shm.unlink()
stream_shm.close()
cap.release()
cv2.destroyAllWindows()세부적인 스킬보단 전체 흐름을 대강 보는게 더 중요할 것 같아 별도의 refactoring은 거치지 않았습니다. frame을 어떻게 shared memory buffer에 저장하는지만 보시면 되겠습니다. 이 부분만 대강 보고서 gpt한테 짜 달라면 잘 짜 줄거에요.
Receiver.py
from multiprocessing import shared_memory
import numpy as np
import cv2
TARGET_WIDTH = 960
TAREGET_HEIGHT= 540
TARGET_DEPTH = 3
def arr_steam_player(shm_name, shape=(TAREGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH)):
# Shared Memory 테스트용, shared 메모리로부터 배열을 받아서,
# print('[arr_stream] getting ')
existing_shm = shared_memory.SharedMemory(name=shm_name)
shared_a = np.frombuffer(existing_shm.buf, dtype=np.uint8)
c = np.ndarray(shape, dtype=np.uint8, buffer=existing_shm.buf)
print(type(c))
print(shared_a.shape, c.shape)
while True:
cv2.imshow('SharedMemory_player', c)
if cv2.waitKey(int(1000 / 24)) == ord('q'):
break
existing_shm.unlink()
existing_shm.close()
# 영상 파일과 창 닫기
cv2.destroyAllWindows()
if __name__ == '__main__':
arr_steam_player('shm')Broadcaster.py에 저장된 shared memory의 shape을 복원하여 opencv로 출력하고 있습니다. 마찬가지로 보내는 측과 받는 측의 데이터 serialization/deserialization 과정만 보시면 되겠습니다.
Result
송신측과 수신측의 shared memory의 이름과, 통신할 이미지의 크기만 맞춰주면 데이터가 서로 다른 프로세스 간에 전송되는 것을 보실 수 있습니다. 사실 만든지는 오래 되었는데 맥에서 구현해보니 sharedmemory 이름을 못 찾는 문제가 생겨서 포스팅 늦추다 이제서야 올립니다. 아마 sharedmemory 구현 방식이 posix 환경과 win32api를 활용하는 과정에서 미묘하게 다른 동작을 보이는 모양입니다. 이미지 ipc 구현을 위한 별도의 임시 파일을 만들어서, 서로의 shared memory 이름와 shape를 공유하는 식으로 코드를 작성한다면 맥에서도 큰 문제 없이 작동할 것으로 보입니다.
Shape을 다르게 해 보면 어떨까?
여기에서는 보내는 측의 shape이(960,540,3) 이었습니다. 받는 측도 동일하게 설정된 상태라 정상적으로 나왔습니다. 여기에서, 받는 측의 shape이 조금 다르다면 어떻게 될까요?
import numpy as np
import cv2
# TARGET_WIDTH = 960
# TAREGET_HEIGHT= 540
TARGET_WIDTH = 1080
TAREGET_HEIGHT= 480
TARGET_DEPTH = 3960*540 = 518400인데, 1080*480 역시 518400으로 같습니다. 그렇다면 어찌저찌 하여 프레임의 데이터를 잘 표시할 수 있을 것만 같습니다. 실행시켜보면 다음과 같이 나옵니다.
나오긴 하는데 어쩐지 찌그러져 보입니다. 이번에는 599*539으로 1픽셀씩 모자르게 deserialization된 데이터를 보겠습니다.
우리가 아날로그 TV의 노이즈에서 보는 것과 비슷한 현상이 발생하는 것을 볼 수 있습니다. 비단 아날로그TV 뿐 아니라, 이미지를 디스플레이 드라이버에서 디스플레이로 전달하는 데 문제가 생길 수도 있습니다. 이런 문제로 아이패드 미니6의 젤리스크롤 현상이 이슈가 되었습니다. 지금 우리가 테스트한 것 처럼 어떤 데이터 소스로부터 영상을 받아서 표현하는데 문제가 생기는가 하면, 이미지 센서로부터 값을 한 번에 모두 읽어오는 데도 비슷한 문제가 발생할 수 있음을 확인할 수 있습니다. 각자 문제의 원인은 조금씩 다르지만, 병목에 의해 문제가 발생했다는 점에서는 흥미롭게 볼 수 있겠습니다. 다음의 글들을 읽어보세요.
Global shutter VS Rolling Shutter 비교 | Vieworks Machine Vision Blog
움직이는 물체를 촬영하면 Rolling shutter 에서는 젤로 현상이 발생합니다. 그래서 Global shutter가 항상 좋다고 생각하는 분들이 많습니다. 하지만 글로벌 셔터와 롤링 셔터는 서로 다른 장단점을 갖
visionblog.vieworks.com
아이패드 미니6 젤리스크롤이 생기는 이유
전세계 공통 현상 디스플레이에 민감하신 분들이 몇몇 계십니다. 이번에 아이패드 미니 6세대를 구매하신 분들 중에서는 이 현상을 불편해하시는 분들이 많을 거라 봅니다. 글쎄요.. 뭐가 이상
yeobie-kim.tistory.com
Done!
gpt가 나오기 전까지만 해도 이런 정보는 삽질을 통해서만 얻어낼 수 있는 값진 결과였습니다. 예전같았으면 신나서 공유했겠지만, 이제는 gpt가 대강 초안을 잘 잡아주니 별로 흥미가 생기질 않습니다. 그래서 좀 포스팅을 미룬 경향이 있었습니다. 근데 한 편으로 생각해보니 gpt만 가지고 코딩을 하다 보면 이런 생각이 필요한 상황에서 gpt의 대화창에 갇혀 새로운 생각 자체를 못하는 케이스가 많아지더라구요. 어찌 보면 당연한 일입니다. 그리고 그 부분에서 저는 개발자의 앞날을 바라보고 싶습니다. 전자시계가 나왔다고 오토매틱 시계가 죽지 않았듯, 인력거꾼이 택시기사로 바뀌었듯, 개발자도 어느 순간 그 성격이 바뀌는 날이 올겁니다. 코더인지 엔지니어인지는 시간과 제 커리어가 답을 해 주겠죠..?
** 본 문서는 다음 내용을 참고하여 작성되었습니다.
[Python] Process간 Numpy Array 공유하기 -2편
devocean.sk.com
긴 글 읽어주셔서 감사합니다. ❤️와 광고 클릭으로 고마움을 간단히 표현할 수 있습니다.
개발 환경(Desktop) | Ryzen 5900X, RTX3080
개발 환경(Laptop) | M1 Macbook Air, M2 Macbook Pro
AI, IoT 제품 개발 및 기타 문의 | dokixote@wklabs.io